iPAS AI應用規劃師 初級
L11401 鑑別式AI與生成式AI的基本原理
出題方向
1
基本定義與目標
2
核心原理與機制
3
主要差異與比較
4
代表模型與應用
5
優點、限制與挑戰
#1
★★★★★
下列何者最能描述鑑別式 AI(Discriminative AI)的主要目標?
答案解析
鑑別式 AI的核心目標是學習如何區分不同的類別。它著重於學習條件機率分佈 P(Y|X),即給定輸入 X 時,輸出 Y 的機率。這意味著模型學習的是如何劃分不同類別之間的決策邊界,以便進行分類(如判斷圖片是貓還是狗)或回歸預測。選項 A 描述的是生成式 AI的目標。選項 C 雖然生成式 AI可以做到,但不是鑑別式 AI的目標。選項 D 描述的是強化學習(Reinforcement Learning)的目標。
#2
★★★★★
下列何者最能描述生成式 AI(Generative AI)的主要目標?
答案解析
生成式 AI的核心目標是學習數據的模式與分佈,並基於此學習結果來創造新的、原始的內容,例如生成新的圖片、文本、音樂等。它著重於學習聯合機率分佈 P(X, Y) 或邊緣機率分佈 P(X)。選項 B 是鑑別式 AI的分類目標。選項 C 是異常偵測的目標。選項 D 是鑑別式 AI的回歸目標。
#3
★★★★
鑑別式模型(Discriminative Model)通常直接學習以下哪種機率?
答案解析
鑑別式模型的目標是區分不同的類別,它直接對給定輸入 X 條件下輸出 Y 的機率進行建模,即條件機率 P(Y|X)。例如,邏輯回歸(Logistic Regression)和支持向量機(SVM)都是典型的鑑別式模型。生成式模型則通常學習聯合機率 P(X, Y) 或邊緣機率 P(X)。
#4
★★★★
生成式模型(Generative Model)通常學習以下哪種機率,以便能夠生成新的資料?
答案解析
生成式模型的目標是理解數據的內在結構與分佈,以便能夠生成新的數據。為了做到這一點,它需要學習數據的整體樣貌,這通常透過學習聯合機率分佈 P(X, Y)(如果同時考慮輸入和輸出)或邊緣機率分佈 P(X)(如果只考慮生成輸入數據本身)來實現。學習了這些分佈後,模型就可以從中採樣,生成新的、符合該分佈的數據點 X 或 (X, Y)。選項 A 是鑑別式模型學習的對象。選項 D 最大概似估計是一種學習模型參數的方法,而不是模型直接學習的機率分佈本身。
#5
★★★★★
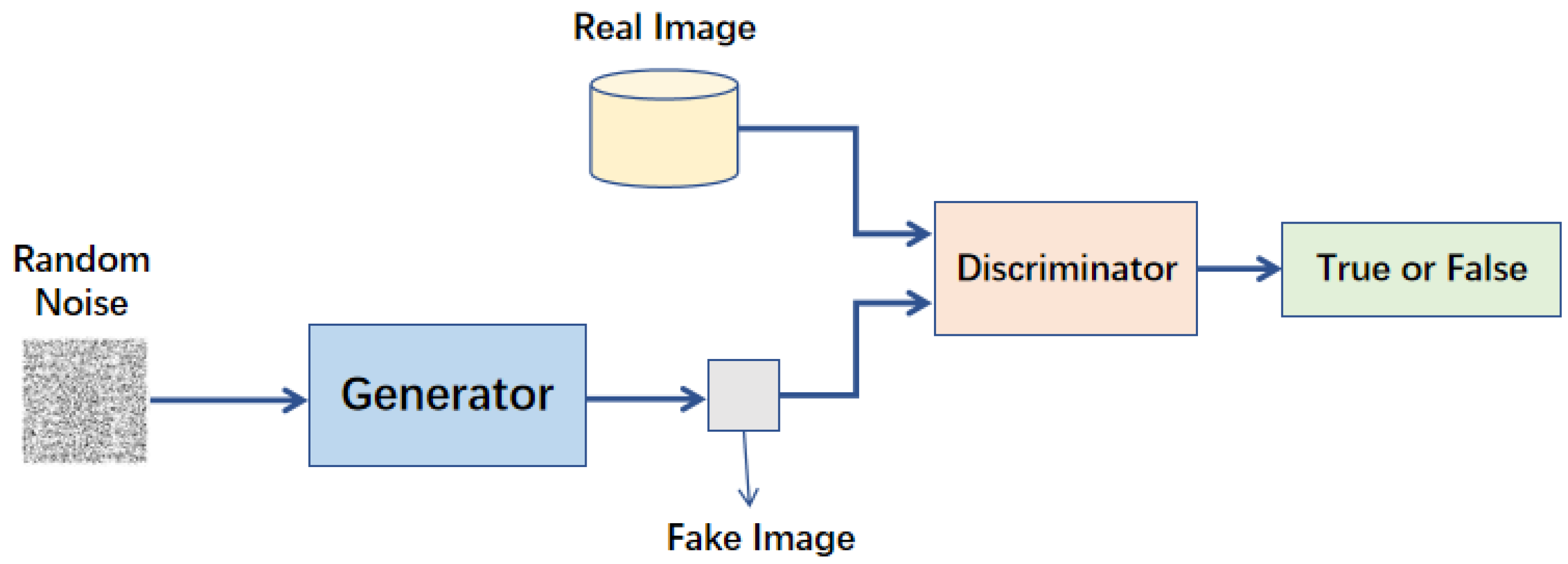
生成對抗網路(GAN, Generative Adversarial Network)包含哪兩個核心組成部分?
答案解析
GAN 是一種著名的生成式模型,其核心思想是透過兩個神經網路的對抗過程來學習生成數據。這兩個網路分別是:
1. 生成器 (Generator): 負責生成看起來像真實數據的假數據。
2. 鑑別器 (Discriminator): 負責判斷輸入的數據是真實的還是由生成器生成的假數據。
這兩個網路相互競爭、共同進化,最終生成器能生成非常逼真的數據,而鑑別器難以區分真假。選項 A 是自編碼器(Autoencoder)或序列到序列模型(Seq2Seq)的組成。選項 B 是卷積神經網路(CNN)的組成。選項 D 是強化學習中常用的組成部分。
#6
★★★★
下列哪種模型最常用於圖像分類任務,屬於鑑別式 AI 的範疇?
答案解析
CNN 由於其卷積層能有效提取圖像的空間層次特徵,被廣泛且成功地應用於圖像分類、目標檢測等任務,這些任務的目標是將輸入圖像區分到預定義的類別中,屬於典型的鑑別式任務。GAN 和自編碼器是生成式模型,主要用於生成新數據或數據降維/特徵提取。RNN 主要用於處理序列數據,如自然語言處理。
#7
★★★★
相較於鑑別式 AI,生成式 AI 的一個主要特點是什麼?
答案解析
生成式 AI 的核心能力在於學習數據分佈並生成新的、原創的內容。它不僅僅是複製或分類現有數據,而是能夠創造出與訓練數據相似但全新的樣本。選項 A 是鑑別式 AI 的主要目標。選項 B 生成式 AI 可以使用有標籤或無標籤數據,甚至純粹基於噪聲生成。選項 D 生成式模型(尤其是現代的如 GAN、Transformer)通常結構非常複雜。
#8
★★★
哪種類型的 AI 模型更適合用於描述資料是如何生成的?
答案解析
生成式模型的目標是學習數據的潛在分佈 P(X) 或 P(X, Y),這使它們能夠理解資料生成的過程和模式。因此,它們更適合描述資料是如何生成的。鑑別式模型專注於學習類別間的邊界 P(Y|X),並不直接關心資料本身的生成過程。強化學習關注的是策略學習。監督式學習是一個更廣泛的類別,鑑別式模型是其中的一種主要形式。
#9
★★★★
在生成式 AI 中,"幻覺"(Hallucination)指的是什麼現象?
答案解析
"幻覺"(Hallucination)是生成式 AI(尤其是大型語言模型)中常見的問題,指的是模型生成了看似流暢、合理,但實際上與事實不符、缺乏依據或完全錯誤的資訊。這並非創意表現,而是模型內部知識缺陷或生成過程失控的結果。過度擬合是模型訓練中的問題,但與幻覺不完全等同。準確預測新資料是模型泛化能力的體現,與幻覺相反。
#10
★★★
相比生成式模型,鑑別式模型在哪些任務上通常表現更好?
答案解析
鑑別式模型的設計目標就是學習輸入和輸出標籤之間的區別或映射關係 (P(Y|X)),因此它們在需要明確分類(判斷屬於哪個類別)或回歸(預測一個連續值)的任務上通常表現更直接且效果更好。選項 B 是生成式模型的典型應用。選項 C 和 D 生成式模型(如自編碼器)和鑑別式模型(如單類支持向量機)都可以應用,但分類和回歸是鑑別式模型最核心的優勢領域。
#11
★★★★
變分自編碼器(VAE, Variational Autoencoder) 主要屬於哪一類 AI 模型?
答案解析
VAE 是一種生成式模型。它包含一個編碼器將輸入數據映射到一個潛在空間(Latent Space)的機率分佈,以及一個解碼器從潛在空間中採樣並生成新的數據。其核心目標是學習數據的潛在表示並生成新數據,因此屬於生成式模型。雖然它使用了編碼器和解碼器的結構,但其目標是生成,而非僅僅是分類或回歸。
#12
★★★
鑑別式 AI 通常需要哪種類型的訓練資料?
答案解析
鑑別式 AI 的目標是學習從輸入 X 到輸出 Y 的映射關係 P(Y|X)。為了學習這種關係,模型需要知道每個輸入 X 對應的正確輸出 Y(即標籤)。因此,鑑別式 AI 通常(尤其是在監督式學習Supervised Learning的框架下)需要帶有標籤的訓練資料。選項 B 和 C 描述的是非監督式學習的資料。選項 D 是強化學習需要的。
#13
★★★★
從模型輸出的角度看,鑑別式 AI 和 生成式 AI 的主要區別是什麼?
答案解析
鑑別式 AI 的目的是區分或預測,其輸出通常是輸入數據所屬的類別標籤(如"貓"、"狗")或一個預測值(如房價)。而生成式 AI 的目的是創造,其輸出是全新的、與訓練數據相似的資料樣本(如一張新的圖片、一段新的文字)。這是兩者在功能和輸出上的根本區別。
#14
★★★
如果你想訓練一個模型來寫詩,你應該優先考慮哪種類型的 AI?
答案解析
寫詩是一種內容創造任務,需要模型能夠生成新的文本序列。這正是生成式 AI 的核心能力。基於 Transformer 架構的大型語言模型(如 GPT 系列)在文本生成方面表現出色,非常適合用於寫詩、寫故事等任務。選項 A、B、D 都是典型的鑑別式模型,主要用於分類或預測,不擅長生成新的、連貫的文本內容。
#15
★★★
判斷一封電子郵件是否為垃圾郵件,這種任務通常由哪種類型的 AI 模型來完成?
答案解析
判斷郵件是否為垃圾郵件是一個典型的二元分類(Binary Classification)任務,目標是將輸入的郵件區分為"垃圾郵件"或"非垃圾郵件"兩個類別。這類任務正是鑑別式 AI 所擅長的。例如,可以使用樸素貝葉斯(Naive Bayes)、SVM 或CNN/RNN 等模型來完成。生成式模型如 GAN 或自編碼器主要用於生成數據或特徵學習,不直接用於分類。
#16
★★★★
在 GAN 中,生成器 (Generator) 的主要作用是什麼?
答案解析
GAN 中的生成器 (Generator) 是一個神經網路,它的輸入通常是隨機噪聲(Random Noise),其目標是學習將這些噪聲轉換成與訓練數據分佈相似的新數據樣本(假數據),目的是欺騙鑑別器。選項 A 是鑑別器的作用。選項 C 是損失函數計算的一部分,但不是生成器的主要作用。選項 D 類似於編碼器的作用。
#17
★★★★
在 GAN 中,鑑別器 (Discriminator) 的主要作用是什麼?
答案解析
GAN 中的鑑別器 (Discriminator) 是一個二元分類器,它的任務是接收一個數據樣本(可能是真實數據,也可能是生成器產生的假數據),並判斷該樣本是真實的還是假的。它的目標是盡可能準確地區分真假數據。選項 B 是生成器的作用。選項 C 類似編碼器。選項 D 是 GAN 整體訓練目標的一部分,但鑑別器本身的作用是判斷真偽。
#18
★★★
下列關於鑑別式 AI 與生成式 AI 的敘述,何者不正確?
答案解析
訓練數據的需求量取決於具體的模型、任務複雜度和數據質量,不能一概而論鑑別式 AI 一定比生成式 AI 需要更少的數據。雖然鑑別式模型有時在特定分類任務上可以用相對較少的數據達到不錯的效果,但複雜的鑑別式模型也可能需要大量數據。同時,現代的生成式模型(如大型語言模型)通常需要極其龐大的數據集進行預訓練,但某些生成式模型(如在特定領域微調)或某些技術(如少樣本學習)也可能在數據較少時運作。因此 D 的說法過於絕對,是錯誤的。
#19
★★★
生成式 AI 在產生內容時可能出現的主要挑戰之一是?
答案解析
生成式 AI 雖然強大,但在內容生成時面臨諸多挑戰,其中最突出的包括:真實性(可能產生幻覺或錯誤信息)、原創性(可能生成與現有內容過於相似甚至重複的內容,涉及版權問題)以及偏見(可能從訓練數據中學習並放大社會偏見)。計算速度(選項 A)雖然可能是問題,但更核心的是內容質量。生成式 AI 非常擅長處理非結構化數據(選項 B)。現代生成式模型通常非常複雜(選項 D)。
#20
★★★★
鑑別式 AI 和 生成式 AI 的根本區別在於它們對數據的______方式不同。
答案解析
兩者的根本區別在於它們對數據進行建模的方式和目標不同。鑑別式 AI 對條件機率 P(Y|X) 建模,旨在學習如何區分類別。生成式 AI 對聯合機率 P(X, Y) 或邊緣機率 P(X) 建模,旨在學習數據的內在分佈以生成新數據。數據儲存、視覺化和清洗雖然都是 AI 流程的一部分,但不是區分這兩類 AI 的根本方式。
#21
★★★
大型語言模型 (LLM, Large Language Model) 如 GPT 主要基於哪種生成式架構?
答案解析
現代的大型語言模型,如 GPT(Generative Pre-trained Transformer)、BERT 等,其核心架構是 Transformer。Transformer 架構利用自注意力機制(Self-Attention Mechanism)來捕捉輸入序列中的長距離依賴關係,非常適合處理自然語言任務,並具備強大的文本生成能力,使其成為生成式 AI 的重要基石。GAN 和 VAE 也是生成式模型,但主要應用於圖像生成等領域。CNN 主要用於圖像處理。
#22
★★
擴散模型 (Diffusion Model) 近年在哪個領域的生成式 AI 應用中取得了顯著成功?
答案解析
擴散模型 (Diffusion Model) 是一種生成式模型,它透過模擬一個逐漸向數據添加噪聲(前向過程),然後學習如何從噪聲中逆向恢復數據(反向過程)來生成樣本。近年來,擴散模型在生成高質量、高解析度圖像方面取得了突破性進展,例如 DALL-E 2、Stable Diffusion 等模型。文本摘要、股票預測和情感分析通常不是擴散模型的主要應用領域。
#23
★★★
相較於鑑別式模型,訓練生成式模型(特別是 GAN)時,一個常見的挑戰是什麼?
答案解析
訓練 GAN 的過程涉及到生成器和鑑別器之間的動態博弈,這個過程可能非常不穩定。有時生成器可能只學會生成少數幾種能夠騙過鑑別器的樣本,而無法覆蓋真實數據的多樣性,這種現象被稱為模式崩潰(Mode Collapse)。這使得 GAN 的訓練比許多鑑別式模型更具挑戰性。模型收斂不一定快(A),需要仔細調整超參數(C),並且可以處理無標籤數據(D)。
#24
★★
下列何者不是鑑別式 AI 的主要應用場景?
答案解析
人臉辨識(判斷是否為某人)、情感分析(判斷文本情感是正面、負面或中性)和疾病診斷輔助(根據症狀判斷可能疾病)都屬於分類或預測任務,是鑑別式 AI 的典型應用。創作音樂則是生成新的內容,屬於生成式 AI 的範疇。
#25
★★
下列何者不是生成式 AI 的主要應用場景?
答案解析
生成文章摘要、根據文字描述生成圖片(文生圖)和自動編寫程式碼都涉及到生成新的內容(文本、圖像、程式碼),是生成式 AI 的應用場景。預測房價是一個典型的回歸(Regression)任務,目標是根據輸入特徵預測一個連續的數值,屬於鑑別式 AI 的範疇。
#26
★★★
如果一個 AI 模型的目標是學習 P(輸入資料),它屬於哪種類型?
答案解析
學習輸入資料的機率分佈 P(X) 是生成式模型的一個核心目標。理解了 P(X),模型就能夠從這個分佈中進行採樣,從而生成新的、符合原始數據分佈特徵的輸入資料 X。鑑別式模型則學習 P(Y|X)。
#27
★★★★
相較於傳統的軟體開發,開發生成式 AI 應用時,哪個因素通常更需要被關注?
答案解析
生成式 AI 的訓練高度依賴大量數據,如果訓練數據本身存在偏見(如性別、種族偏見),模型很可能會學習並放大這些偏見。同時,生成式 AI 產生的內容可能涉及錯誤資訊、歧視性言論、侵犯版權等多種倫理風險。因此,在開發生成式 AI 應用時,數據偏見和倫理風險是比傳統軟體開發更需要特別關注的問題。其他選項雖然也是軟體開發的考量,但相對來說,倫理風險在生成式 AI 中更為突出。
#28
★★★
哪種 AI 模型通常不直接輸出機率值作為預測?
答案解析
支持向量機 (SVM) 的主要目標是找到一個最大間隔超平面(Maximum Margin Hyperplane)來區分不同的類別。它的原始輸出是樣本點到超平面的距離或符號,並不直接輸出屬於某個類別的機率值。雖然可以透過一些後續處理(如 Platt Scaling)將 SVM 的輸出轉換為機率,但其核心機制並非基於機率建模。相比之下,邏輯回歸、樸素貝葉斯以及使用 Softmax 輸出的神經網路,其輸出都可以直接解釋為類別機率。
#29
★★★
文字轉圖像(Text-to-Image)模型,如 Stable Diffusion,主要利用了哪種 AI 技術原理?
答案解析
文字轉圖像任務的目標是根據輸入的文字描述生成全新的、對應的圖像。這是一個典型的內容生成任務,因此主要利用生成式 AI 的技術原理。Stable Diffusion 等模型正是基於擴散模型(Diffusion Model)這一生成式技術。鑑別式方法用於分類或預測,強化學習用於策略學習,非監督式聚類用於數據分群,均不直接適用於生成圖像。
#30
★★★★
從應用角度來看,如果你的主要目標是理解數據的內在結構和模式,哪種類型的模型可能更有幫助?
答案解析
生成式模型通過學習數據的潛在機率分佈,旨在捕捉數據的內在結構、模式和變異性。因此,如果目標是深入理解數據本身的特性,而不僅僅是進行分類或預測,生成式模型通常能提供更豐富的洞察。鑑別式模型更側重於找到區分不同類別的邊界,可能不會深入學習數據的完整分佈。